on
如何自动删除索引中到期的日志数据?
一、业务场景
在业务系统建设过程中,随着大数据、AI技术的发展,对日志数据的收集和分析也变得愈发重要,在不影响业务系统的情况下,尽可能第一时间完整的存储日志数据变为一个刚性需求。然而业务系统一般只对近期的日志数据有一定需求,有没有好的办法既能实现业务系统对近期日志数据的查询需求,又能实现完整日志数据的灵活管理呢?
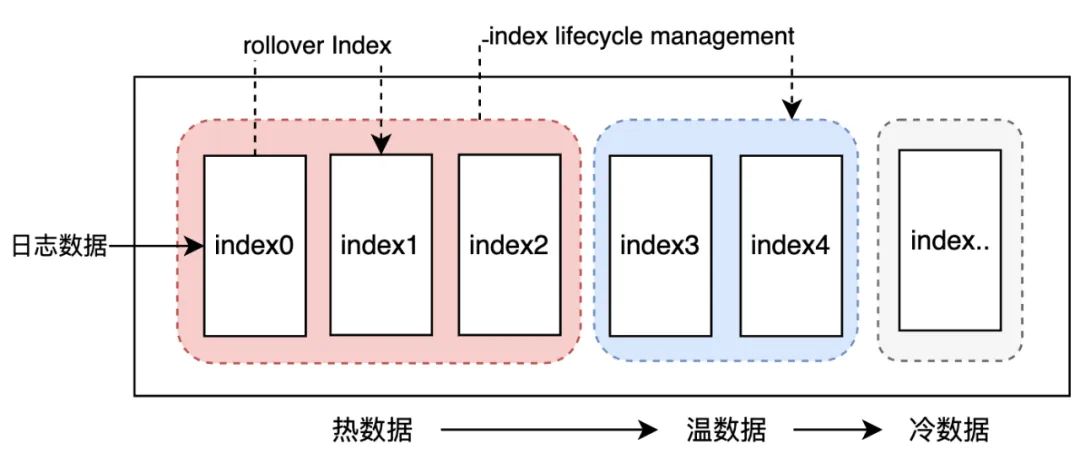
在日志方面的解决方案中,ELK是一个非常便捷、高效的组合。ElasticSearch给我们提供了对应的非常重要的特性Rollover Index(滚动索引)和ILM(索引生命周期管理)可以实现上述的需求。通过滚动索引我们可以实现数据定量切割,不断把新的数据写入最新的索引中;通过索引生命周期管理则可以实现历史数据的归档及删除。
二、特性介绍
索引模板(index template)
elasticsearch是一个分布式搜索引擎,如果想高效利用存储进去的数据,则需要进行良好的mapping设计,对存储数据进行结构定义、字段类型设计。在一个索引被创建时(不管是手动方式还是自动方式),如果索引名称与一个索引模板所定义的名称规则匹配,那么该索引的数据将会按照该模板的定义的格式和方式进行存储和加工。
滚动索引(rollover index)
索引是一个适用于读多写少场景的数据格式,针对源源不断没有边界的流式数据,合理的控制索引文件的大小以及数据范围是一个好的设计,保证对近期数据(热数据)的高效处理是具备更高优先级的选择。滚动索引允许我们对索引数据根据设定的条件值(阈值)对索引文件进行一个切割,把新的数据切换写到新的索引文件上。滚动索引可以通过手动方式(Rollover API)进行,也可以根据生命周期管理(ILM)实现自动触发滚动。
条件值conditions
| 参数名 | 参数说明 |
|---|---|
| max_age | 索引创建之后最大生存生命周期 |
| max_docs | 索引最大存储文档数 |
| max_size | 索引总的最大存储体积 |
| max_primary_shard_size | 索引主分片最大存储体积 |
| max_primary_shard_docs | 索引主分片最大存储文档数 |
索引生命周期管理(Index Lifecycle Management)
ILM在6.6版本中属于beta特性,6.7正式GA发布。在数据治理理念中,数据从出生到结束,经历的不同的阶段产生的价值也不同,所以在技术上,也可以进行相对应选择不同的加工方式来挖掘数据的价值,同时降低存储和加工的成本。
ElasticSearch默认定义了生命周期5个阶段:
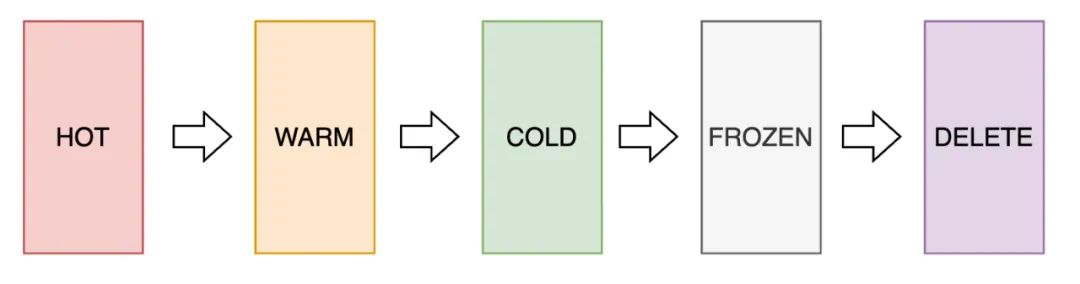
- HOT:数据还会被更新和检索
- WARM:不再更新,还在被检索
- COLD:不再更新,偶尔被检索,为保证数据完整性而存在,允许慢查询
- FROZEN:不再更新,极少被检索,允许慢查询
- DELETE:不再被需要,可删除处理
三、实践步骤
1. 创建索引模板
首先初始化索引模板,模板中index.lifecycle.rollover_alias定义了索引滚动时,索引写入别名为collect_log。aliases中的别名collect_log_search为全局检索别名,通过该别名检索数据,则是查询全部的完整的数据。
同时该模板也定义了索引生命周期所对应的策略名称为collect_log_policy,策略中设定了索引生命周期阶段切换的条件。
PUT /_template/索引模板名称/?include_type_name=false
{
"index_patterns": "collect_log-*",
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"index.lifecycle.name": "collect_log_policy",
"index.lifecycle.rollover_alias": "collect_log"
},
"mappings": {
"properties": {
"tenantId": {
"type": "keyword"
},
"planId": {
"type": "keyword"
},
"instanceId": {
"type": "keyword"
},
"message": {
"type": "text"
},
"time": {
"type": "date"
}
}
},
"aliases": {
"collect_log_search": {}
}
}
2. 创建ILM策略
ILM策略中,并不需要全部定义默认的5个阶段,需要注意的是时效方面的条件是进入该阶段后开始计时。比如下方的策略中delete阶段min_age为30天,是指数据从hot切换到delete之后数据保留30天再删除。
PUT /_ilm/policy/策略名称
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "5GB",
"max_age": "7d"
}
}
},
"delete": {
"min_age": "30d",
"actions": {
"delete": {}
}
}
}
}
}
# 查看所有策略的定义
GET _ilm/policy?pretty
3. 设定生命周期检查间隔
ilm策略设定了conditions之后,并不会马上就能实现索引自动滚动。需要进一步检查全局参数,设置生命周期检查间隔。处于性能方面的考虑,建议检查间隔不宜过于频繁。
查看全局设置:
GET _cluster/settings?pretty
{
"persistent" : { },
"transient" : {
"indices" : {
"lifecycle" : {
"poll_interval" : "1m"
}
}
}
}
设置生命周期检查间隔配置:
PUT _cluster/settings
{
"transient": {
"indices.lifecycle.poll_interval": "1d"
}
}
4. 写入数据
完成上述配置之后,就可以使用模板中的写入别名进行数据写入了。还有一个需要注意的点:初始化第一个索引时,索引的名称需要符合滚动索引名称的规范的要求,需要设置一个可以滚动递增的数字尾缀(如:XXXX_LOG-000001),否则索引初始化时会有检查异常抛出。
为了验证滚动是否生效,全局检查周期可以临时设置一个较短的间隔,策略中也可以设置一个较小/较快触发的条件。
5. 查看索引生命周期阶段
在验证过程中,可以通过下面的方法查看索引所处在的生命周期在哪个阶段。
GET collect_log_164667804295168/_ilm/explain?pretty
{
"indices" : {
"collect_log_164667804295168-000002" : {
"index" : "collect_log_164667804295168-000002",
"managed" : true,
"policy" : "collect_log_policy",
"lifecycle_date_millis" : 1654849350471,
"phase" : "hot",
"phase_time_millis" : 1654849350508,
"action" : "rollover",
"action_time_millis" : 1654849410496,
"step" : "check-rollover-ready",
"step_time_millis" : 1654849410496,
"phase_execution" : {
"policy" : "collect_log_policy",
"phase_definition" : {
"min_age" : "0ms",
"actions" : {
"rollover" : {
"max_docs" : 100
}
}
},
"version" : 3,
"modified_date_in_millis" : 1654848795192
}
}
}
}